

結論/要点まとめ
- リトルエンディアンとは、データを下位バイトから先にメモリへ並べる方式のこと。
- ビッグエンディアンは人が読む順番どおり(上位バイトから)並べる方式。両者の違いは「バイトを置く順番」だけ。
- 例:
0x12345678はリトルでは 78 56 34 12、ビッグでは 12 34 56 78 の順で格納される(本記事下部で実測検証済み)。 - x86/x64(IntelやAMDのPC・サーバ)はリトル、ネットワーク通信はビッグが標準。
リトルエンディアンとは?まず一言で

リトルエンディアンとは、複数バイトのデータをメモリに格納するとき、一番下の位(下位バイト)から先に並べていく方式です。「エンディアン(Endian)」はバイトを並べる順序のルールを指す言葉で、その並べ方には大きく2種類あります。それがリトルエンディアンと、対になるビッグエンディアンです。
普段プログラムを書いていると「数値は数値」として扱えますが、メモリやファイル、通信といった1バイト単位の世界に降りた瞬間、この「順番」が問題になります。ここを理解しておくと、バイナリ解析や通信プログラムで「数値が逆さまに見える」現象に慌てずに済みます。
「下位バイトから先に並べる」方式
2桁以上の16進数で書かれた値には、桁ごとに「重み」があります。たとえば 0x12345678 という4バイトの値では、0x12 が最上位バイト(一番重い桁)、0x78 が最下位バイト(一番軽い桁)です。
リトルエンディアンは、この軽い桁(下位バイト)からメモリの先頭アドレスに詰めていきます。人間の感覚では逆さまに見えますが、CPUにとっては計算上の都合がよい並べ方です。
ビッグエンディアンとの違いを図解で理解する
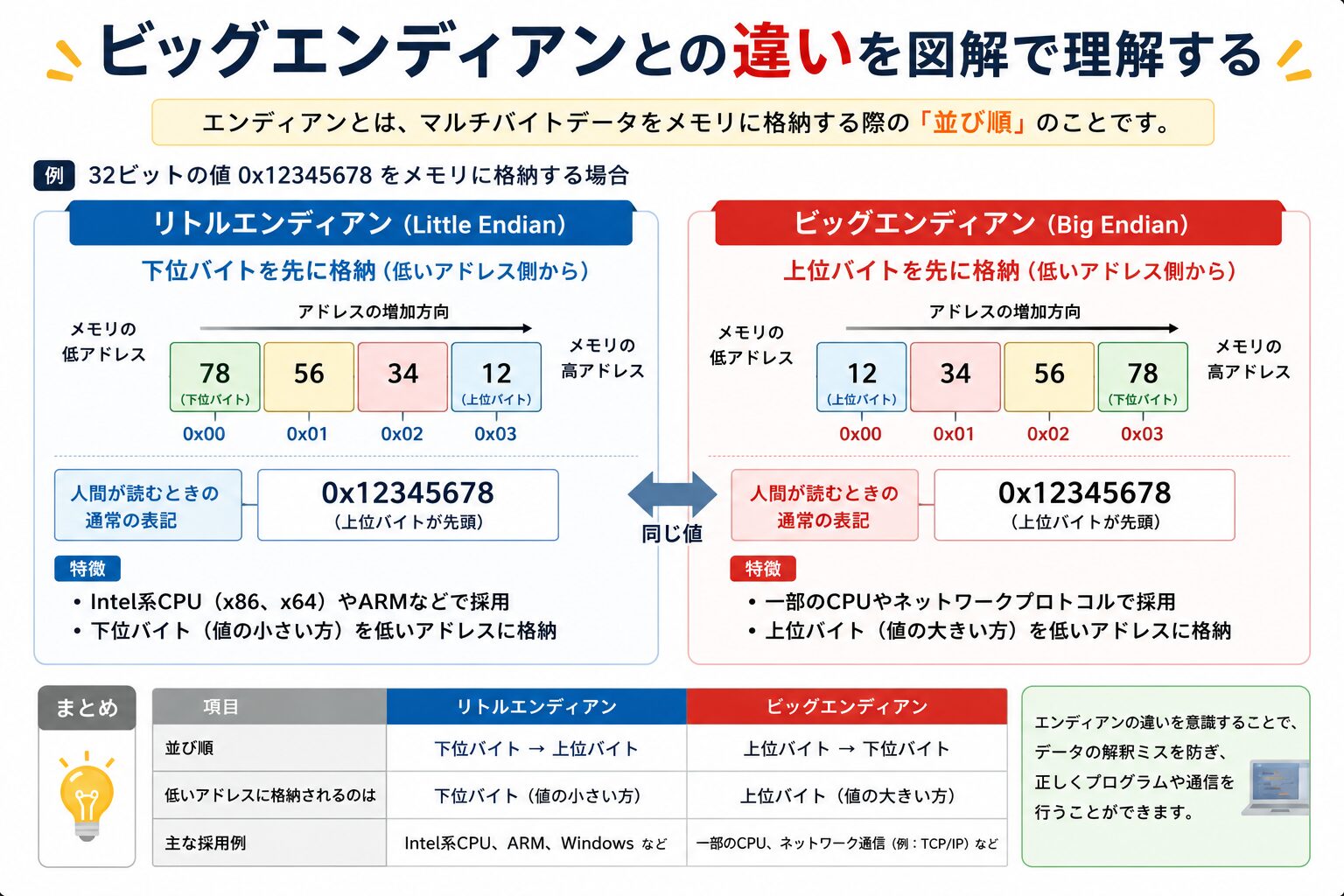
言葉だけでは掴みにくいので、同じ値 0x12345678 をメモリ(アドレスが小さい方を左)に置いたときの並びを見比べてみましょう。
0x12345678 をメモリに置くと並びはこうなる
下位バイト(78)が先頭。逆順に見える
上位バイト(12)が先頭。書いた順そのまま
左がアドレスの小さい側です。ビッグエンディアンは 0x12345678 と書いたままの順で並ぶのに対し、リトルエンディアンは 78 56 34 12 とバイト単位で逆順になっているのがわかります。ここで重要なのは、ひっくり返るのは「バイトの順番」だけで、1バイトの中(78や12など)はそのままだという点です。ビット単位で逆さまになるわけではありません。
色で覚える:リトル=逆順、ビッグ=そのまま
試験対策で「どっちがどっち?」を一発で覚えたいなら、次の対応で十分です。
| 項目 | リトルエンディアン | ビッグエンディアン |
|---|---|---|
| 並べる順 | 下位バイトから | 上位バイトから |
| 0x12345678 | 78 56 34 12 | 12 34 56 78 |
| 見た目 | 逆順に見える | 書いたまま |
| 別名 | ― | ネットワークバイトオーダー |
| 覚え方 | 「小さい位がリトル=先頭」 | 「大きい位がビッグ=先頭」 |
「リトル(小さい)=小さい位から」と語呂で結びつけると忘れにくくなります。
なぜ2種類のエンディアンが存在するのか
「どちらかに統一すればいいのに」と思うところですが、歴史的に別々のCPUメーカーが、それぞれ都合のよい方式を採用してきたため2種類が残りました。
リトルエンディアンには、下位バイトが常に先頭アドレスに来るという利点があります。たとえば4バイトの値を「下位1バイトだけ取り出す」「2バイトの値として読み直す」といった操作をするとき、読み始めるアドレスを変えなくてよいため、CPU内部の演算回路をシンプルに作れます。Intel系がこの方式を採ったことで、PC・サーバの世界ではリトルが事実上の標準になりました。
一方ビッグエンディアンは、人がダンプ(16進表示)を読んだときに値がそのまま読めるのが利点です。可読性を重視する場面や、機種が混在しても順序がブレないことが求められる通信の世界で標準として採用されました。そのためビッグエンディアンは「ネットワークバイトオーダー」とも呼ばれます。
どこで使われている?CPU・用途別の違い
実際にどちらの方式が使われているかは、CPUやプロトコルによって決まっています。代表的なものを整理します。
| 対象 | エンディアン | 補足 |
|---|---|---|
| x86 / x64(Intel・AMD) | リトル | 一般的なPC・サーバ。最も遭遇する |
| ARM | 主にリトル | 切替可能だが多くはリトルで動作(スマホ等) |
| RISC-V | 主にリトル | 標準はリトル |
| 旧PowerPC / SPARC | ビッグ | 古いワークステーション・サーバ系 |
| TCP/IP(通信) | ビッグ | ネットワークバイトオーダー |
| PNG・JPEGなど一部の形式 | ビッグ | ファイルフォーマットで規定 |
| BMP・一部の形式 | リトル | 形式ごとに異なるので要確認 |
ポイントは、手元のCPU(多くはリトル)と通信(ビッグ)でエンディアンが食い違うことです。だからこそネットワークプログラミングでは、送信前に値をビッグへ変換する処理が必要になります。
実務でハマりやすいトラブルと対処
エンディアンを意識せずにバイト列を扱うと、次のような「数値が逆さま」「想定の値にならない」トラブルが起きます。
よくある症状
- バイナリファイルを読み込んだら、数値が想定の何百万倍・何億倍にもなっていた
- 別のCPUで動かしたら、同じデータなのに数値だけ変わってしまった
- 通信で送った数値が、受信側で全く違う値として解釈された
対処の基本は、「どのエンディアンで保存・送信されたデータか」を仕様で確認し、自分の環境に合わせて変換することです。通信では送信時にホスト順からネットワーク順(ビッグ)へ、受信時に逆向きへ変換する関数(C言語の htonl / ntohl など)を使うのが定石です。ファイルを扱う場合も、フォーマット仕様にエンディアンが明記されているので、それに従って読み込み時に並べ替えます。
逆にいえば、同じCPU・同じ環境の中だけで完結するなら、エンディアンを意識する必要はほぼありません。問題になるのは「異なる環境の間でバイト列をやり取りするとき」だけ、と覚えておくと整理しやすくなります。
言語別:エンディアンを確認・変換するコード例
実務では「自分の環境がどちらか」「データを別のエンディアンに変換する」場面が出てきます。代表的な言語での書き方をまとめました。
Python:struct と sys.byteorder で一発
Pythonは標準ライブラリの struct で、エンディアンを記号で指定してバイト列へ変換できます。< がリトル、> がビッグです。
import struct, sys
# 自分の環境のエンディアンを確認
print(sys.byteorder) # 'little' or 'big'
# 0x12345678 を4バイト整数としてバイト列に変換
struct.pack('<I', 0x12345678) # リトル → b'\x78\x56\x34\x12'
struct.pack('>I', 0x12345678) # ビッグ → b'\x12\x34\x56\x78'
# バイト列から数値に戻す(読み込み側)
struct.unpack('<I', b'\x78\x56\x34\x12') # (305419896,) = 0x12345678int.from_bytes() / int.to_bytes() でも byteorder='little' のように文字列で指定でき、こちらの方が読みやすい場面もあります。
C言語:通信なら htonl / ntohl が定番
ネットワークプログラミングでは、ホスト(多くはリトル)とネットワーク(ビッグ)の変換を専用関数で行うのが定石です。
#include <arpa/inet.h>
uint32_t host = 0x12345678;
// 送信時:ホスト順 → ネットワーク順(ビッグ)へ
uint32_t net = htonl(host); // host to network long
// 受信時:ネットワーク順 → ホスト順へ
uint32_t back = ntohl(net); // network to host long
// 16bit版は htons / ntohs を使うこれらの関数は「ホストが元々ビッグエンディアンなら何もしない」ように作られているため、環境を問わず安全に使えるのが利点です。自分でバイトを並べ替えるより、まずこの関数を使うのが基本になります。
実際にPythonで検証してみた
ここまでの説明が本当に正しいか、当サイトで実際にPython(CPython 3系)を動かして確かめました。検証環境は sys.byteorder が little を返す、一般的なリトルエンディアンのマシンです。教科書の数字ではなく、手元で実行して得た生の結果を載せます。
検証1:同じバイト列が約1677万倍の差になる(トラブルの実測)
「数値が想定の何百万倍にもなる」というトラブルが、実際にどれくらいの差になるのかを再現しました。たった4バイト 01 00 00 00 を、リトルとビッグそれぞれで「4バイト整数」として読み込ませた結果がこちらです。
実測結果(同じバイト列 01 00 00 00 を解釈)
| リトルとして読む | 1 |
|---|---|
| ビッグとして読む | 16,777,216 |
| 差 | 約 1677万倍 |
同一のバイト列でも、解釈するエンディアンを間違えるだけで「1」が「1677万」に化けることが確認できました。これがバイナリ解析で値が桁違いになる正体です。
検証2:FF(1のバイト)の位置はこう動く(5パターンの実測)
どのバイトが移動するのかを直感的に掴むため、FF を1か所だけ含む値を5パターン用意し、リトル/ビッグで格納した結果を並べました。FFが左右にスライドしていく様子がそのまま「バイトが逆順になる」動きです。
| 元の値 | リトル(実測) | ビッグ(実測) |
|---|---|---|
| 0x000000FF | FF 00 00 00 | 00 00 00 FF |
| 0x0000FF00 | 00 FF 00 00 | 00 00 FF 00 |
| 0x00FF0000 | 00 00 FF 00 | 00 FF 00 00 |
| 0xFF000000 | 00 00 00 FF | FF 00 00 00 |
| 0x12345678 | 78 56 34 12 | 12 34 56 78 |
リトル側ではFFが上から下へ向かうほど右へ、ビッグ側では左へ動いており、両者がちょうど鏡写しの関係になっているのが実測でも確認できました。なお2バイト(short)の 0xABCD でも試したところ、リトルは CD AB、ビッグは AB CD となり、バイト数が変わっても「バイト単位で逆順」というルールは一貫していました。
検証3:文字列・小数・マイナスはどうなる?よくある誤解を実測
「文字列や小数もバイトが逆になるの?」という疑問は多いので、こちらも実際に動かして確かめました。結果は直感とズレる部分があり、ここが落とし穴になります。
① 文字列(ASCII/UTF-8)は影響を受けない。1文字が1バイトで完結するため、並べ替えが起きる「複数バイトのまとまり」がそもそも存在しないからです。ただし UTF-16のように1文字を2バイトで表す文字コードは影響を受けます。
| データ | リトル(実測) | ビッグ(実測) |
|---|---|---|
| “ABCD”(UTF-8) | 41 42 43 44 | 41 42 43 44(同じ) |
| “AB”(UTF-16) | 41 00 42 00 | 00 41 00 42 |
| 3.14(float単精度) | C3 F5 48 40 | 40 48 F5 C3 |
② 小数(float)もしっかり逆順になる。3.14 はリトルで C3 F5 48 40、ビッグで 40 48 F5 C3 と、整数と同じくバイト単位できれいに反転しました。浮動小数点も内部は単なるバイトの並びなので、エンディアンの対象です。
③ マイナスの値には”見分けがつかない”罠がある。4バイトの -1 をリトル・ビッグ両方で出力したところ、どちらも FF FF FF FF で完全に同じになりました。
実測結果(マイナス値の落とし穴)
| -1 をリトルで格納 | FF FF FF FF |
|---|---|
| -1 をビッグで格納 | FF FF FF FF |
| -2 をリトルで格納 | FE FF FF FF |
| -2 をビッグで格納 | FF FF FF FE |
-1 は全ビットが1(FF FF FF FF)のため、逆順にしても同じ並びになり区別できません。一方 -2 なら FE の位置が左右で入れ替わり、ちゃんと違いが現れます。「テスト値に -1 を使うとエンディアンのバグを見逃す」という、実務で知っておきたい注意点です。
まとめると、影響を受けるのは「2バイト以上をひとまとまりで扱う数値・文字コード」であり、1バイトで完結するASCII文字は対象外、という線引きになります。テストする際は、-1のような左右対称になる値ではなく、0x12345678 のように全バイトが異なる値を使うのが確実です。
関連用語をまとめて整理
エンディアンの理解を深めるうえで、セットで覚えておきたい用語を整理します。
| 用語 | 意味 |
|---|---|
| バイトオーダー | 複数バイトのデータをメモリに並べる順序のこと。エンディアンとほぼ同義で使われる。 |
| ネットワークバイトオーダー | 通信で標準とされるバイト順=ビッグエンディアンの別名。TCP/IPで規定。 |
| MSB(最上位バイト/ビット) | Most Significant Byte/Bit。一番「重い」桁。0x12345678なら 0x12 がMSB側。 |
| LSB(最下位バイト/ビット) | Least Significant Byte/Bit。一番「軽い」桁。0x12345678なら 0x78 がLSB側。 |
| ミドルエンディアン | リトル・ビッグの中間的な並びを取る方式。ごく一部の旧式システムで使われた特殊例。 |
| BOM(バイトオーダーマーク) | テキストファイル先頭に置く印で、UTF-16などでエンディアンを判別させるためのもの。 |
「リトル=LSBから先に並べる」「ビッグ=MSBから先に並べる」と、MSB/LSBの言葉で言い換えられるようにしておくと、試験の選択肢でも迷わなくなります。
よくある質問(FAQ)
リトルとビッグ、どちらが優れているのですか?
優劣はありません。リトルはCPUの演算回路をシンプルにしやすく、ビッグは人が16進ダンプを読みやすいという、それぞれ別の利点があります。現在のPC・サーバではリトルが主流、通信ではビッグが標準、という棲み分けで定着しています。
ビット単位でも逆さまになるのですか?
いいえ。エンディアンが入れ替えるのは「バイトの順番」だけで、1バイト内のビットの並びは変わりません。0x78 は逆順でも 0x78 のままです。
自分のPCがどちらか確認する方法はありますか?
一般的なWindows・MacのPCはIntelやAMD、Apple Silicon搭載でいずれもリトルエンディアンで動作しています。Pythonなら sys.byteorder を実行すると ‘little’ のように現在の環境が一目で分かります。
なぜ「エンディアン」という名前なのですか?
小説『ガリバー旅行記』で、ゆで卵を「とがった方(リトルエンド)から割る派」と「太い方(ビッグエンド)から割る派」が争う話が由来とされています。どちらでも本質は変わらないのに対立する、という風刺が、エンディアン論争になぞらえられました。
まとめ
リトルエンディアンは「下位バイトから先に並べる方式」で、0x12345678 なら 78 56 34 12 とバイト単位で逆順に格納されます(本記事で実測検証済み)。ビッグエンディアンは書いたままの順で、こちらは通信の標準(ネットワークバイトオーダー)です。
覚えるべき要点は3つだけです。①入れ替わるのはバイトの順番だけ ②x86・x64などPCはリトル、通信はビッグ ③問題になるのは異なる環境の間でデータをやり取りするときだけ。この3点を押さえておけば、試験でも実務でもエンディアンに振り回されることはなくなります。実際に検証2で見たように、同じバイト列でも解釈を誤れば1677万倍の差が生まれるため、異なる環境をまたぐときは必ずエンディアンを確認しましょう。
研究をシェア!
